Judith Neve

Projects
Master’s thesis: Evaluating tuning strategies for random forest hyperparameters with regards to prediction performance of clinical prediction models and computational time (2022-2023)
Supervisors: Dr. Maarten van Smeden | Zoë Dunias | Dr. Ben van Calster
Tuning models can take hours - but is it worth it? In this project, I decided to explore how different tuning strategies affect model predictive performance and whether longer, more exhaustive procedures pay off. I did so by programming three simulation studies in R, executed via slurm on a high-performance computer.
GitHub repository | Shiny app visualising results
Undergraduate dissertation: The evolution of data sharing practices in the psychological literature (2020-2021)
Supervisor: Dr. Guillaume Rousselet
This project focused on evaluating the rate at which data is shared and how it is shared over time. I combined data from three different sources and performed analyses in R. This study is published in Meta-Psychology!
OSF project | Preprint
Classification algorithm (2023)
I took part in a project aiming to classify mushrooms as edible or poisonous based on a variety of visual characteristics. Multiple algorithms were used and compared.
GitHub repository
Gibbs sampler (2022)
In order to deepen my understanding of Bayesian approaches, I have coded the entirety of a Gibbs sampler.
GitHub repository
Online statistics lessons (2022)
I worked on making and updating online statistics lessons on the platform Grasple. These lessons are part of the general part of a mandatory Advanced Research Methods and Statistics course for psychology bachelor students.
Testing CTmeta (Oct. 2021-Apr. 2022)
I worked as a research assistant for Dr. Rebecca Kuiper. In that time, I extensively tested functions from the CTmeta R package and edited the documentation.
GitHub fork | Test files
#TidyTuesdays (2020)
I have occasionally taken part in the #TidyTuesdays challenges, which release a dataset each week and participants create visualisations.
GitHub repository
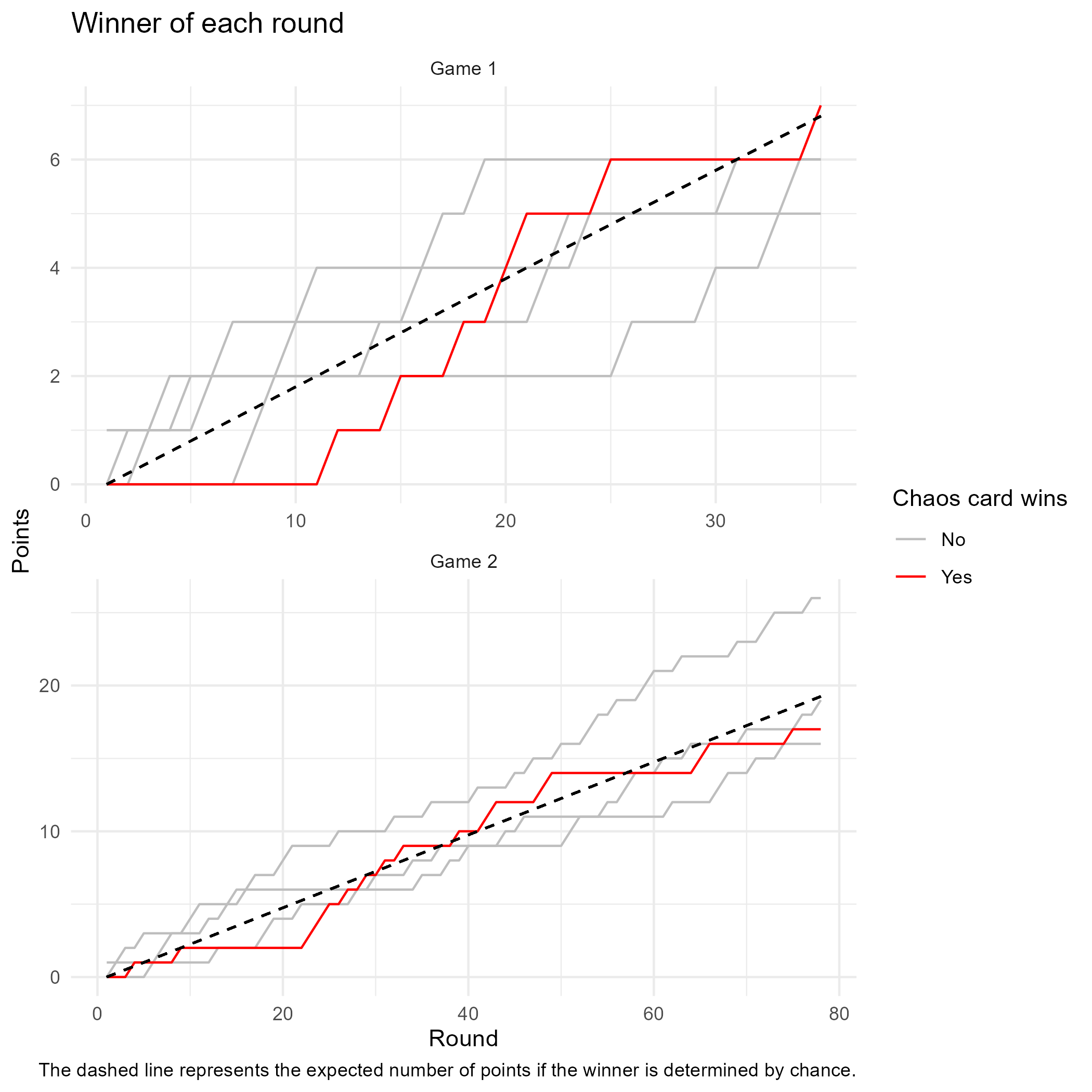
Cards Against Humanity (ongoing)
In April 2020, after a fair few game nights with the people I was living with under lockdown, we started wondering whether a randomly added card in a Cards Against Humanity round was increasingly likely to win as the game went on. I took it upon myself to start collecting data to test this hypothesis - while my sample size is too small to draw meaningful conclusions so far, the project is ongoing and some visualisations do exist!